In this blog post I will explain how you can make an Angular app work with WebAssembly code. This combination of technologies can bring interesting advantages to web development and it is fairly simple to implement.
As I write this post, Angular is currently at version 5.1 and WebAssembly is still in its initial version, but it is making fast progress since Chrome, Edge, Firefox, and WebKit have reached a consensus on the binary format and API (see their roadmap).
Create the Angular App
Let’s start with the Angular app. If you are not familiar with Angular, you should visit its website and read its quick start guide and related documentation. You should be able to easily create a boilerplate app with the ng command (see angular CLI). We can start creating a new project called “ng-wasm”:
ng new ng-wasm
The generated project will have some basic source code and configuration files ready to be used. You should be able to serve the app right away and test it with the following command:
ng serve --open
The app should load on the web browser at http://localhost:4200/
Create the WebAssembly Code
The second step now is the creation of the WebAssembly code. If you are not familiar with WebAssembly, you should visit their website and go through the documentation. You will have to download and install the emsdk package.
Angular will need access to the WASM code we will create, so the easiest solution for us is to create a cpp folder inside the src folder of the Angular project. The Angular project should then have a structure that looks like this:
ng-wasm/
+-- e2e/
+-- node_modules/
+-- src/
+-- app/
+-- assets/
+-- cpp/ <-- NEW FOLDER
+-- environments/
Inside the cpp/ folder let’s create a file called main.c with the following C code:
#include <string.h> #include <emscripten/emscripten.h> double EMSCRIPTEN_KEEPALIVE multiply(double a, double b) { return a * b; } int EMSCRIPTEN_KEEPALIVE get_length(const char* text) { return strlen(text); } int main() {}
Basically we have implemented two C functions that we will be able to call from Angular. Note that we have to decorate these functions with EMSCRIPTEN_KEEPALIVE, which prevents the compiler from inlining or removing them.
emcc \
-O3 \
-s WASM=1 \
-s "EXTRA_EXPORTED_RUNTIME_METHODS=['ccall']" \
-o webassembly.js \
main.c
Note that I compile the C code with optimizations on (-O3 parameter), which makes the output more compact and efficient (if possible). The WASM=1 option tells the compiler to generate WebAssembly code (without this parameter, it would generate asm.js code instead). The EXTRA_EXPORTED_RUNTIME_METHODS=[‘ccall’] option is needed because we want to call the C functions from Javascript using the Module.ccall() javascript function (see the Angular code in the next section). I encourage you to read more about these parameters and play with them in order to see what errors or changes you will get.
- webassembly.js — Javascript glue code that helps loading the webassembly code (wasm)
- webassembly.wasm — Intermediate binary code to be used by the browser to generate machine code
The WebAssembly code is now ready to be used. Let’s go back to the Angular project now.
Modify the Angular Project
The default project created by the angular CLI contains an app/ folder with the following contents (among other files):
ng-wasm/
+-- src/
+-- app/
+-- app.component.ts
+-- app.component.html
+-- app.component.css
Let’s change the app.component.ts file to have the following code:
import { Component } from '@angular/core'; declare var Module: any; @Component({ selector: 'app-root', templateUrl: './app.component.html', styleUrls: ['./app.component.css'] }) export class AppComponent { multiplyResult: number; getLengthResult: number; multiply(a: number, b: number): void { this.multiplyResult = Module.ccall( 'multiply', // function name 'number', // return type ['number', 'number'], // argument types [a, b] // parameters ); } getLength(s: string): void { this.getLengthResult = Module.ccall( 'get_length', // function name 'number', // return type ['string'], // argument type [s] // parameter ); } }
In this code we implement two methods of the AppComponent class that will forward the call to our WebAssembly code generated in the previous section.
The first thing you should notice is the “declare var Module: any” at the top of the file. This is the typescript way of saying “there is a global variable named Module that I want to use in this scope”.The Module variable is actually a Javascript object used by the WebAssembly glue code. We declare it using type “any” because we don’t want typescript to complain about the things we will do with it. You should NOT do that in production code. It should be fairly simple for you to create a typescript definition file with class and method signatures (see my previous blog post where I discuss this).
Inside the multiply() member function we can call WebAssembly code using the Module.ccall() javascript function:
Module.ccall(
'multiply', // function name
'number', // return type
['number', 'number'], // argument types
[a, b] // parameters
);
In such call we pass the function name, return type, argument types and actual parameters to the binary function.
Now let’s change the app.component.html code in order to build our user interface:
<button (click)="multiply(10.5, 21.2)"> Call multiply(10.5, 21.2) </button> <div *ngIf="multiplyResult"> multiply result is {{ multiplyResult }} </div> <button (click)="getLength('Testing String Length')"> Call length('Testing String Length') </button> <div *ngIf="getLengthResult"> get_length result is {{ getLengthResult }} </div>
This HTML code adds two buttons to the page. The first button will call the multiply() function with two parameters (10.5 and 21.2), and the second button will call the getLength() function with “Testing String Length” parameter.
The Last Step
If you try to serve the existing source code with the ng serve command, you will notice that Angular doesn’t automatically load the WebAssembly code we have added to the src/cpp/ folder. We have to manually change the index.html file (inside the src/ folder) and add the following code snippet to the end of the <head> section:
‹script› var Module = { locateFile: function(s) { return 'cpp/' + s; } }; ‹/script› ‹script src="cpp/webassembly.js"›‹/script›
This code imports the Javascript glue code generated by the WebAssembly compiler, but it also defines a Module.locateFile() function that will be used by WebAssembly to find the WASM file. By default, WebAssembly will try to find the WASM file at the root level of the application. In our case, we keep that file inside the cpp/ folder, so we have to prepend that folder’s name to the file path.
Now everything should be fine to go and the app should look like the screen below (with a bit of CSS makeup).

Conclusion
Angular and WebAssembly are two great technologies that can be used together without too much effort. There is no secret in this combination since both technologies are designed to work with web browsers and Javascript code is a common byproduct of their operations.
WebAssembly is still under development, but it has a huge potential towards native code performance, which is a dream yet to come true for web applications. Its roadmap is full of amazing features that serious web developers should never turn their back on.











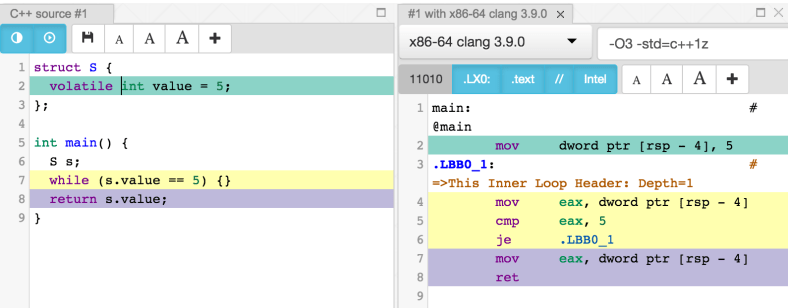
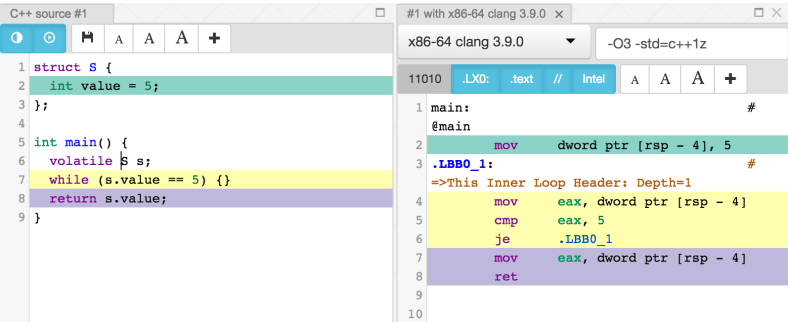
 Please look at the image on the left. Why on earth would someone call a banana a “curved yellow fruit”?! OK, it is curved, it is yellow and it is a fruit, but WTF?
Please look at the image on the left. Why on earth would someone call a banana a “curved yellow fruit”?! OK, it is curved, it is yellow and it is a fruit, but WTF? The UI should never surprise the user. If it does, then the designer has failed to do a good job. One example of this problem is a link that doesn’t look clickable. This is actually conflicting with the idea that UIs should be clear and intuitive. How can something be surprising and intuitive at the same time?
The UI should never surprise the user. If it does, then the designer has failed to do a good job. One example of this problem is a link that doesn’t look clickable. This is actually conflicting with the idea that UIs should be clear and intuitive. How can something be surprising and intuitive at the same time?

 One of the ideas behind simplicity is that UIs should be understandable and easy to read. The clock on the left is an example of how things can get critical if you must read it immediately. Of course you know the position of the numbers, but imagine different situations where you must read them (e.g., the clock is rotated 90 degrees). Since you need some seconds to calculate the numbers, this will distract (and even disturb) you more than needed. By the way, what time does the clock show right now?
One of the ideas behind simplicity is that UIs should be understandable and easy to read. The clock on the left is an example of how things can get critical if you must read it immediately. Of course you know the position of the numbers, but imagine different situations where you must read them (e.g., the clock is rotated 90 degrees). Since you need some seconds to calculate the numbers, this will distract (and even disturb) you more than needed. By the way, what time does the clock show right now? Which animal is this? Is this a cat? A bunny? Some people say it is a small camel! Use your imagination 😛
Which animal is this? Is this a cat? A bunny? Some people say it is a small camel! Use your imagination 😛
 We all know that accessibility features (in general) are used by just a small group of users. But if you decide to implement them, please make sure they are really useful in practice. If you don’t know what I mean, please look at the image on the left.
We all know that accessibility features (in general) are used by just a small group of users. But if you decide to implement them, please make sure they are really useful in practice. If you don’t know what I mean, please look at the image on the left. You can’t create good interfaces if you don’t know your users. Things can get more difficult if they are aliens, but it is always possible to figure out what they really want. Talk to your users (maybe using a translator helmet) and try to understand how the see the world (not only our world, but also their world).
You can’t create good interfaces if you don’t know your users. Things can get more difficult if they are aliens, but it is always possible to figure out what they really want. Talk to your users (maybe using a translator helmet) and try to understand how the see the world (not only our world, but also their world).

 Another problem related to icons is best explained when we look at the image on the right. At first glance, you might see a dentist with a patient. But if you look closer, you might note a dirty second meaning. Would you let your wife go to that dentist? I don’t think so…
Another problem related to icons is best explained when we look at the image on the right. At first glance, you might see a dentist with a patient. But if you look closer, you might note a dirty second meaning. Would you let your wife go to that dentist? I don’t think so… Look at this second example. By placing both signs together, it is inevitable to imagine people hunting children. When the worker placed the second sign, he probably saw the problem, but he didn’t care. He might have thought that the problem was with him, not with other people.
Look at this second example. By placing both signs together, it is inevitable to imagine people hunting children. When the worker placed the second sign, he probably saw the problem, but he didn’t care. He might have thought that the problem was with him, not with other people. Isn’t that yummy? This might be good for your cholesterol levels.
Isn’t that yummy? This might be good for your cholesterol levels. This sign is in Portuguese, but I don’t think we need a translation here. The problem is right ahead and it is difficult to understand why people keep repeating the same information again and again. What worries me is the fact that they do that too often.
This sign is in Portuguese, but I don’t think we need a translation here. The problem is right ahead and it is difficult to understand why people keep repeating the same information again and again. What worries me is the fact that they do that too often.

 Sometimes too much precision can be useless. Take a closer look at the next sign and let me know if that extra half mile is important to you. Information like that is inappropriate for the situation and only adds noise and clutter. Drivers usually have just a few seconds to read a sign and the more information you add, the worse it will be. The same applies to software UI.
Sometimes too much precision can be useless. Take a closer look at the next sign and let me know if that extra half mile is important to you. Information like that is inappropriate for the situation and only adds noise and clutter. Drivers usually have just a few seconds to read a sign and the more information you add, the worse it will be. The same applies to software UI.
 A sentence with a wrong meaning is worse than a typo. That’s the case of our next sign: If your worries aren’t strong enough to kill you, the church can give *them* a hand.
A sentence with a wrong meaning is worse than a typo. That’s the case of our next sign: If your worries aren’t strong enough to kill you, the church can give *them* a hand. Alignment is important because users don’t read text on the UI. They scan it. So, well aligned text and controls can help dividing the screen into digestible pieces of information. Unfortunately this isn’t the case of our next picture. After reading the first sign, I wonder if people hire cats to make burgers with their flesh.
Alignment is important because users don’t read text on the UI. They scan it. So, well aligned text and controls can help dividing the screen into digestible pieces of information. Unfortunately this isn’t the case of our next picture. After reading the first sign, I wonder if people hire cats to make burgers with their flesh. At last, remember that your creativity can connect the user with a whole new experience. Let your imagination fly when you build user interfaces, as it happens with the guys from the last picture. Good interfaces make users forget their computers pretty much like readers forget their books when they read good stories.
At last, remember that your creativity can connect the user with a whole new experience. Let your imagination fly when you build user interfaces, as it happens with the guys from the last picture. Good interfaces make users forget their computers pretty much like readers forget their books when they read good stories.